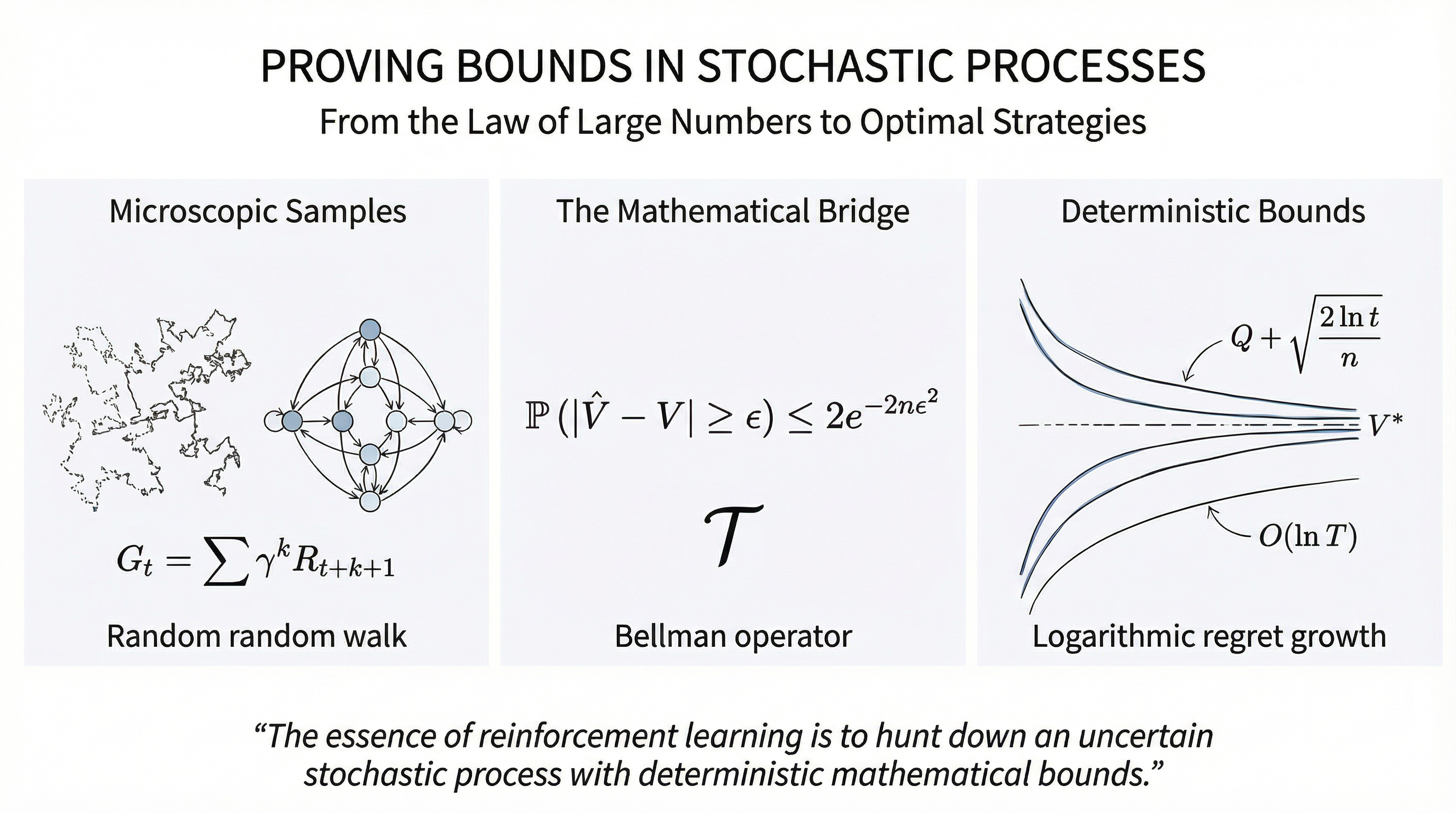
The essence of reinforcement learning is to hunt down an uncertain stochastic process with deterministic mathematical bounds. All our efforts are to make these bounds ever tighter.
"Chance is only the measure of our ignorance." — Henri Poincaré
为了在随机环境中构建最优决策序列,我们首先必须剥离感性的“经验”,转而寻求一种类似于力学公理的数学表述。在经典的物理范式中,系统的演化由初始条件与确定性的微分方程共同决定;而在智能体(Agent)互动的范式下,我们面对的是一种更加混沌的动力学:系统不仅受制于环境的随机波动,还受制于智能体干预产生的路径偏差。本笔记将摒弃一切算法实现的枝节,从第一性原理出发,推演序列决策如何从随机过程演化为确定的算子收敛问题。
The mechanical foundation of sequential decision-making: MDP (Markov Decision Process)
建立决策理论的首要任务是精确定义状态空间及其演化律。我们定义一个由状态空间 S \mathcal{S} S A \mathcal{A} A t t t S t ∈ S S_t \in \mathcal{S} S t ∈ S A t ∈ A A_t \in \mathcal{A} A t ∈ A P ( s ′ ∣ s , a ) P(s' \mid s, a) P ( s ′ ∣ s , a ) S \mathcal{S} S
马尔可夫决策过程(MDP)的结构完整性建立在马尔可夫公设之上。该性质断言,系统未来的演化仅取决于当前状态 S t S_t S t { S 0 , … , S t − 1 } \{S_0, \dots, S_{t-1}\} { S 0 , … , S t − 1 }
P ( S t + 1 ∣ S t , A t , … , S 0 , A 0 ) = P ( S t + 1 ∣ S t , A t ) \begin{equation}
\mathbb{P}(S_{t+1} \mid S_t, A_t, \dots, S_0, A_0) = \mathbb{P}(S_{t+1} \mid S_t, A_t)
\end{equation} P ( S t + 1 ∣ S t , A t , … , S 0 , A 0 ) = P ( S t + 1 ∣ S t , A t ) 这意味着 S t S_t S t S \mathcal{S} S R ( s , a ) R(s, a) R ( s , a ) V π ( s ) V^\pi(s) V π ( s ) γ ∈ [ 0 , 1 ) \gamma \in [0, 1) γ ∈ [ 0 , 1 )
贝尔曼算子与不动点定理一旦确立了 MDP 框架,决策目标便转化为寻找一个最优策略 π ∗ ∈ A S \pi^* \in \mathcal{A}^{\mathcal{S}} π ∗ ∈ A S V π V^\pi V π
V π ( s ) = ∑ a ∈ A π ( a ∣ s ) [ R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) V π ( s ′ ) ] \begin{equation}
V^\pi(s) = \sum_{a \in \mathcal{A}} \pi(a|s) \left[ R(s, a) + \gamma \sum_{s' \in \mathcal{S}} P(s' \mid s, a) V^\pi(s') \right]
\end{equation} V π ( s ) = a ∈ A ∑ π ( a ∣ s ) [ R ( s , a ) + γ s ′ ∈ S ∑ P ( s ′ ∣ s , a ) V π ( s ′ ) ] 该方程的深刻之处在于它将全局无穷轨迹的求和转化为局部的算子映射。我们可以定义一个线性贝尔曼算子 T π : R ∣ S ∣ → R ∣ S ∣ \mathcal{T}^\pi: \mathbb{R}^{|\mathcal{S}|} \to \mathbb{R}^{|\mathcal{S}|} T π : R ∣ S ∣ → R ∣ S ∣ V π V^\pi V π
Complete Metric Spaces and Bellman Operators
我们定义一个函数空间 V \mathcal{V} V S \mathcal{S} S V : S → R V: \mathcal{S} \to \mathbb{R} V : S → R L ∞ L_\infty L ∞
d ( V , U ) = ∥ V − U ∥ ∞ = max s ∈ S ∣ V ( s ) − U ( s ) ∣ \begin{equation}
d(V, U) = \|V - U\|_\infty = \max_{s \in \mathcal{S}} |V(s) - U(s)|
\end{equation} d ( V , U ) = ∥ V − U ∥ ∞ = s ∈ S max ∣ V ( s ) − U ( s ) ∣ 在此度量下,( V , ∥ ⋅ ∥ ∞ ) (\mathcal{V}, \|\cdot\|_\infty) ( V , ∥ ⋅ ∥ ∞ ) T ∗ : V → V \mathcal{T}^*: \mathcal{V} \to \mathcal{V} T ∗ : V → V
( T ∗ V ) ( s ) = max a ∈ A [ R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) V ( s ′ ) ] \begin{equation}
(\mathcal{T}^* V)(s) = \max_{a \in \mathcal{A}} \left[ R(s, a) + \gamma \sum_{s' \in \mathcal{S}} P(s' \mid s, a) V(s') \right]
\end{equation} ( T ∗ V ) ( s ) = a ∈ A max [ R ( s , a ) + γ s ′ ∈ S ∑ P ( s ′ ∣ s , a ) V ( s ′ ) ] 压缩映射性质的数理推导为了证明 T ∗ \mathcal{T}^* T ∗ V , U ∈ V V, U \in \mathcal{V} V , U ∈ V
∥ T ∗ V − T ∗ U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ , γ < 1 \begin{equation}
\|\mathcal{T}^* V - \mathcal{T}^* U\|_\infty \le \gamma \|V - U\|_\infty, \quad \gamma < 1
\end{equation} ∥ T ∗ V − T ∗ U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ , γ < 1 证明过程:考虑任意状态 s ∈ S s \in \mathcal{S} s ∈ S ( T ∗ V ) ( s ) ≥ ( T ∗ U ) ( s ) (\mathcal{T}^* V)(s) \ge (\mathcal{T}^* U)(s) ( T ∗ V ) ( s ) ≥ ( T ∗ U ) ( s ) a ∗ a^* a ∗ V V V s s s a ∗ = arg max a [ R s , a + γ E [ V ′ ] ] a^* = \arg\max_a [R_{s,a} + \gamma \mathbb{E}[V'] ] a ∗ = arg max a [ R s , a + γ E [ V ′ ]] max \max max
( T ∗ V ) ( s ) − ( T ∗ U ) ( s ) = max a [ R s , a + γ E [ V ′ ] ] − max a [ R s , a + γ E [ U ′ ] ] ≤ [ R s , a ∗ + γ E [ V ′ ] ] − [ R s , a ∗ + γ E [ U ′ ] ] = γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ∗ ) ( V ( s ′ ) − U ( s ′ ) ) ≤ γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ∗ ) ∣ V ( s ′ ) − U ( s ′ ) ∣ ≤ γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ∗ ) ∥ V − U ∥ ∞ = γ ∥ V − U ∥ ∞ \begin{equation}
\begin{aligned}
(\mathcal{T}^* V)(s) - (\mathcal{T}^* U)(s) &= \max_a [R_{s,a} + \gamma \mathbb{E}[V'] ] - \max_a [R_{s,a} + \gamma \mathbb{E}[U'] ] \\
&\le [R_{s,a^*} + \gamma \mathbb{E}[V'] ] - [R_{s,a^*} + \gamma \mathbb{E}[U'] ] \\
&= \gamma \sum_{s' \in \mathcal{S}} P(s' \mid s, a^*) (V(s') - U(s')) \\
&\le \gamma \sum_{s' \in \mathcal{S}} P(s' \mid s, a^*) |V(s') - U(s')| \\
&\le \gamma \sum_{s' \in \mathcal{S}} P(s' \mid s, a^*) \|V - U\|_\infty \\
&= \gamma \|V - U\|_\infty
\end{aligned}
\end{equation} ( T ∗ V ) ( s ) − ( T ∗ U ) ( s ) = a max [ R s , a + γ E [ V ′ ]] − a max [ R s , a + γ E [ U ′ ]] ≤ [ R s , a ∗ + γ E [ V ′ ]] − [ R s , a ∗ + γ E [ U ′ ]] = γ s ′ ∈ S ∑ P ( s ′ ∣ s , a ∗ ) ( V ( s ′ ) − U ( s ′ )) ≤ γ s ′ ∈ S ∑ P ( s ′ ∣ s , a ∗ ) ∣ V ( s ′ ) − U ( s ′ ) ∣ ≤ γ s ′ ∈ S ∑ P ( s ′ ∣ s , a ∗ ) ∥ V − U ∥ ∞ = γ ∥ V − U ∥ ∞ 由于该不等式对所有状态 s s s ∥ T ∗ V − T ∗ U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ \|\mathcal{T}^* V - \mathcal{T}^* U\|_\infty \le \gamma \|V - U\|_\infty ∥ T ∗ V − T ∗ U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ γ \gamma γ T ∗ \mathcal{T}^* T ∗
所以根据巴拿赫不动点定理(Banach Fixed-Point Theorem),由于 γ < 1 \gamma < 1 γ < 1 T π \mathcal{T}^\pi T π L ∞ L_\infty L ∞ V 0 V_0 V 0 T ∗ V ( s ) = max a [ R ( s , a ) + γ E [ V ( s ′ ) ∣ s , a ] ] \mathcal{T}^* V(s) = \max_a [R(s, a) + \gamma \mathbb{E}[V(s') \mid s, a]] T ∗ V ( s ) = max a [ R ( s , a ) + γ E [ V ( s ′ ) ∣ s , a ]] V ∗ V^* V ∗
估计的裂痕与缩放的必然性尽管贝尔曼方程在解析上趋于完美,但在强化学习的实战范式中,我们遭遇了根本性的障碍:转移核 P P P R R R τ = { s 0 , a 0 , r 1 , s 1 , … } \tau = \{s_0, a_0, r_1, s_1, \dots\} τ = { s 0 , a 0 , r 1 , s 1 , … } V ^ ( s ) \hat{V}(s) V ^ ( s ) G t G_t G t n → ∞ n \to \infty n → ∞ V ^ ( s ) \hat{V}(s) V ^ ( s )
因此,关于“无知边界”的关键问题浮出水面:在给定有限样本的情况下,我们的估计值 V ^ ( s ) \hat{V}(s) V ^ ( s ) V ∗ V^* V ∗
From rectangular scaling to Chebyshev
我们无法直接观测到算子中的期望 E \mathbb{E} E μ ^ n \hat{\mu}_n μ ^ n n n n ϵ \epsilon ϵ
我们将从最粗糙的一阶矩放缩开始进行分析推导。
马尔可夫不等式试图回答的问题是:一阶矩的粗糙边界如果我们对随机变量的分布一无所知,仅知道它的均值(一阶矩),我们能对它的波动做出什么承诺?
对于一个非负随机变量 X ≥ 0 X \ge 0 X ≥ 0 a > 0 a > 0 a > 0 E [ X ] \mathbb{E}[X] E [ X ]
P ( X ≥ a ) ≤ E [ X ] a \begin{equation}
\mathbb{P}(X \ge a) \le \frac{\mathbb{E}[X]}{a}
\end{equation} P ( X ≥ a ) ≤ a E [ X ] 证明过程:引入指示函数 I X ≥ a \mathbb{I}_{X \ge a} I X ≥ a X ≥ a X \ge a X ≥ a X a ≥ 1 ≥ I X ≥ a \frac{X}{a} \ge 1 \ge \mathbb{I}_{X \ge a} a X ≥ 1 ≥ I X ≥ a X < a X < a X < a X a ≥ 0 = I X ≥ a \frac{X}{a} \ge 0 = \mathbb{I}_{X \ge a} a X ≥ 0 = I X ≥ a X ≥ 0 X \ge 0 X ≥ 0 I X ≥ a ≤ X a \mathbb{I}_{X \ge a} \le \frac{X}{a} I X ≥ a ≤ a X
E [ I X ≥ a ] ≤ E [ X a ] ⟹ P ( X ≥ a ) ≤ E [ X ] a \begin{equation}
\mathbb{E}[\mathbb{I}_{X \ge a}] \le \mathbb{E}\left[\frac{X}{a}\right] \implies \mathbb{P}(X \ge a) \le \frac{\mathbb{E}[X]}{a}
\end{equation} E [ I X ≥ a ] ≤ E [ a X ] ⟹ P ( X ≥ a ) ≤ a E [ X ] 马尔可夫不等式是极为“慷慨”且粗糙的。它仅仅利用了均值信息,对偏离的约束力呈线性衰减。在强化学习中,这意味着如果我们只知道平均奖励,我们对“偶尔出现极端坏结果”的防御力几乎为零。然而,它作为所有高级不等式的祖先,奠定了利用矩信息换取概率边界的底层逻辑。
随后切比雪夫不等式为了获得更紧(Tighter)的边界引用二阶矩和方差来介入,所以我们必须引入更高阶的信息。这里我们规定如果我们不仅知道均值 μ \mu μ σ 2 \sigma^2 σ 2
对于任意随机变量 X X X μ \mu μ σ 2 \sigma^2 σ 2 ϵ > 0 \epsilon > 0 ϵ > 0
P ( ∣ X − μ ∣ ≥ ϵ ) ≤ σ 2 ϵ 2 \begin{equation}
\mathbb{P}(|X - \mu| \ge \epsilon) \le \frac{\sigma^2}{\epsilon^2}
\end{equation} P ( ∣ X − μ ∣ ≥ ϵ ) ≤ ϵ 2 σ 2 证明过程:观察事件 { ∣ X − μ ∣ ≥ ϵ } \{|X - \mu| \ge \epsilon\} { ∣ X − μ ∣ ≥ ϵ } ( X − μ ) 2 ≥ ϵ 2 (X - \mu)^2 \ge \epsilon^2 ( X − μ ) 2 ≥ ϵ 2 ( X − μ ) 2 (X - \mu)^2 ( X − μ ) 2
P ( ( X − μ ) 2 ≥ ϵ 2 ) ≤ E [ ( X − μ ) 2 ] ϵ 2 \begin{equation}
\mathbb{P}((X - \mu)^2 \ge \epsilon^2) \le \frac{\mathbb{E}[(X - \mu)^2]}{\epsilon^2}
\end{equation} P (( X − μ ) 2 ≥ ϵ 2 ) ≤ ϵ 2 E [( X − μ ) 2 ] 根据方差的定义 E [ ( X − μ ) 2 ] = σ 2 \mathbb{E}[(X - \mu)^2] = \sigma^2 E [( X − μ ) 2 ] = σ 2
P ( ∣ X − μ ∣ ≥ ϵ ) ≤ σ 2 ϵ 2 \begin{equation}
\mathbb{P}(|X - \mu| \ge \epsilon) \le \frac{\sigma^2}{\epsilon^2}
\end{equation} P ( ∣ X − μ ∣ ≥ ϵ ) ≤ ϵ 2 σ 2 相比马尔可夫不等式的线性衰减,切比雪夫不等式表现出了平方级收敛。这意味着,只要方差有限,随着偏离阈值 ϵ \epsilon ϵ 1 / ϵ 2 1/\epsilon^2 1/ ϵ 2
1 / ϵ 2 1/\epsilon^2 1/ ϵ 2 n n n X ˉ n \bar{X}_n X ˉ n σ 2 n ϵ 2 \frac{\sigma^2}{n\epsilon^2} n ϵ 2 σ 2 n n n
这促使我们思考一个终极命题:如果我们不仅利用一阶矩和二阶矩,而是利用所有阶矩的信息(即通过矩生成函数 M X ( t ) = E [ e t X ] M_X(t) = \mathbb{E}[e^{tX}] M X ( t ) = E [ e tX ]
Hoeffding's inequality
在处理诸如“智能体需要多少样本才能以 99% 的信心判定一个动作是次优的”这类问题时,平方级收敛的速度依然太慢。在强化学习中,由于我们通常处理的是有界奖励(如 r ∈ [ 0 , 1 ] r \in [0, 1] r ∈ [ 0 , 1 ]
我们假设 X 1 , X 2 , … , X n X_1, X_2, \dots, X_n X 1 , X 2 , … , X n X i ∈ [ a i , b i ] X_i \in [a_i, b_i] X i ∈ [ a i , b i ] μ i \mu_i μ i P ( ∑ X i − ∑ μ i ≥ t ) \mathbb{P}(\sum X_i - \sum \mu_i \ge t) P ( ∑ X i − ∑ μ i ≥ t )
直接计算概率分布通常很难,所以我们利用指数函数的单调性和马尔可夫不等式。
P ( Z ≥ a ) ≤ E [ Z ] a \mathbb{P}(Z \ge a) \le \frac{\mathbb{E}[Z]}{a} P ( Z ≥ a ) ≤ a E [ Z ] 但是我们知道马尔可夫不等式要求随机变量必须是非负的,但是 ( X i − μ i ) (X_i - \mu_i) ( X i − μ i )
E [ ∑ ( X i − μ i ) ] = ∑ ( E [ X i ] − μ i ) = ∑ ( μ i − μ i ) = 0 \mathbb{E}[\sum (X_i - \mu_i)] = \sum (\mathbb{E}[X_i] - \mu_i) = \sum (\mu_i - \mu_i) = 0 E [ ∑ ( X i − μ i )] = ∑ ( E [ X i ] − μ i ) = ∑ ( μ i − μ i ) = 0 P ( ⋯ ≥ t ) ≤ 0 t = 0 \mathbb{P}(\dots \ge t) \le \frac{0}{t} = 0 P ( ⋯ ≥ t ) ≤ t 0 = 0 得到的结果是没有任何关于概率分布的有效信息。所以我们引入了一个单调递增的指数函数,做到了强制非负,且指数函数能把较大的偏差极度放大:
P ( ∑ ( X i − μ i ) ≥ t ) = P ( e s ∑ ( X i − μ i ) ≥ e s t ) \begin{equation}
\mathbb{P}\left(\sum (X_i - \mu_i) \ge t\right) = \mathbb{P}\left(e^{s \sum (X_i - \mu_i)} \ge e^{st}\right)
\end{equation} P ( ∑ ( X i − μ i ) ≥ t ) = P ( e s ∑ ( X i − μ i ) ≥ e s t ) 随后根据马尔克夫不等式,我们得到:
P ( ∑ ( X i − μ i ) ≥ t ) ≤ e − s t E [ e s ∑ ( X i − μ i ) ] \begin{equation}
\mathbb{P}\left(\sum (X_i - \mu_i) \ge t\right) \le e^{-st} \mathbb{E}\left[e^{s \sum (X_i - \mu_i)}\right]
\end{equation} P ( ∑ ( X i − μ i ) ≥ t ) ≤ e − s t E [ e s ∑ ( X i − μ i ) ] 利用变量的独立性,累加的期望变成了期望的乘积:
P ( … ) ≤ e − s t ∏ i = 1 n E [ e s ( X i − μ i ) ] \begin{equation}
\mathbb{P}(\dots) \le e^{-st} \prod_{i=1}^n \mathbb{E}\left[e^{s(X_i - \mu_i)}\right]
\end{equation} P ( … ) ≤ e − s t i = 1 ∏ n E [ e s ( X i − μ i ) ] 至此我们得到切尔诺夫界(Chernoff Bound)的通用形式:
P ( X ≥ ϵ ) = P ( e s X ≥ e s ϵ ) ≤ E [ e s X ] e s ϵ = e − s ϵ M X ( s ) \begin{equation}
\mathbb{P}(X \ge \epsilon) = \mathbb{P}(e^{sX} \ge e^{s\epsilon}) \le \frac{\mathbb{E}[e^{sX}]}{e^{s\epsilon}} = e^{-s\epsilon} M_X(s)
\end{equation} P ( X ≥ ϵ ) = P ( e s X ≥ e sϵ ) ≤ e sϵ E [ e s X ] = e − sϵ M X ( s ) 其中 M X ( s ) = E [ e s X ] M_X(s) = \mathbb{E}[e^{sX}] M X ( s ) = E [ e s X ]
这个技巧的精妙之处在于它引入了一个自由参数 s s s s s s X X X M X ( s ) M_X(s) M X ( s )
引理: 设 X X X X ∈ [ a , b ] X \in [a, b] X ∈ [ a , b ] s ∈ R s \in \mathbb{R} s ∈ R
E [ e s X ] ≤ e s 2 ( b − a ) 2 8 \begin{equation}
\mathbb{E}[e^{sX}] \le e^{\frac{s^2(b-a)^2}{8}}
\end{equation} E [ e s X ] ≤ e 8 s 2 ( b − a ) 2 证明思路:利用指数函数的凸性。对于任何 x ∈ [ a , b ] x \in [a, b] x ∈ [ a , b ] a a a b b b
x = b − x b − a a + x − a b − a b \begin{equation}
x = \frac{b-x}{b-a}a + \frac{x-a}{b-a}b
\end{equation} x = b − a b − x a + b − a x − a b 根据 Jensen 不等式(或直接利用 e s x e^{sx} e s x
e s x ≤ b − x b − a e s a + x − a b − a e s b \begin{equation}
e^{sx} \le \frac{b-x}{b-a}e^{sa} + \frac{x-a}{b-a}e^{sb}
\end{equation} e s x ≤ b − a b − x e s a + b − a x − a e s b 对两边取期望 E \mathbb{E} E E [ X ] = 0 \mathbb{E}[X]=0 E [ X ] = 0
E [ e s X ] ≤ b b − a e s a − a b − a e s b \begin{equation}
\mathbb{E}[e^{sX}] \le \frac{b}{b-a}e^{sa} - \frac{a}{b-a}e^{sb}
\end{equation} E [ e s X ] ≤ b − a b e s a − b − a a e s b 为了简化证明,我们引入两个辅助变量:
令 p = − a b − a p = \frac{-a}{b-a} p = b − a − a E [ X ] = 0 \mathbb{E}[X]=0 E [ X ] = 0 a ≤ 0 ≤ b a \le 0 \le b a ≤ 0 ≤ b p ∈ [ 0 , 1 ] p \in [0, 1] p ∈ [ 0 , 1 ] 1 − p = b b − a 1-p = \frac{b}{b-a} 1 − p = b − a b
令 u = s ( b − a ) u = s(b-a) u = s ( b − a )
此时,上述不等式的右侧可以重新表述为关于 u u u ϕ ( u ) \phi(u) ϕ ( u )
ϕ ( u ) = ( 1 − p ) e − p u + p e ( 1 − p ) u \begin{equation}
\phi(u) = (1-p)e^{-pu} + pe^{(1-p)u}
\end{equation} ϕ ( u ) = ( 1 − p ) e − p u + p e ( 1 − p ) u 我们的目标是证明 ϕ ( u ) ≤ e u 2 / 8 \phi(u) \le e^{u^2/8} ϕ ( u ) ≤ e u 2 /8
定义函数 L ( u ) = ln ϕ ( u ) L(u) = \ln \phi(u) L ( u ) = ln ϕ ( u ) L ( u ) ≤ u 2 8 L(u) \le \frac{u^2}{8} L ( u ) ≤ 8 u 2
L ( u ) = ln ( ( 1 − p ) e − p u + p e ( 1 − p ) u ) \begin{equation}
L(u) = \ln \left( (1-p)e^{-pu} + pe^{(1-p)u} \right)
\end{equation} L ( u ) = ln ( ( 1 − p ) e − p u + p e ( 1 − p ) u ) 将其展开:
L ( u ) = − p u + ln ( 1 − p + p e u ) \begin{equation}
L(u) = -pu + \ln \left( 1 - p + pe^u \right)
\end{equation} L ( u ) = − p u + ln ( 1 − p + p e u ) 我们对 L ( u ) L(u) L ( u ) u = 0 u=0 u = 0
一阶导数:
L ′ ( u ) = − p + p e u 1 − p + p e u \begin{equation}
L'(u) = -p + \frac{pe^u}{1 - p + pe^u}
\end{equation} L ′ ( u ) = − p + 1 − p + p e u p e u 代入 u = 0 u=0 u = 0 L ′ ( 0 ) = − p + p 1 = 0 L'(0) = -p + \frac{p}{1} = 0 L ′ ( 0 ) = − p + 1 p = 0
二阶导数:令 q ( u ) = p e u 1 − p + p e u q(u) = \frac{pe^u}{1 - p + pe^u} q ( u ) = 1 − p + p e u p e u L ′ ( u ) = − p + q ( u ) L'(u) = -p + q(u) L ′ ( u ) = − p + q ( u )
L ′ ′ ( u ) = q ′ ( u ) = p e u ( 1 − p + p e u ) − ( p e u ) 2 ( 1 − p + p e u ) 2 = p e u ( 1 − p ) ( 1 − p + p e u ) 2 \begin{equation}
L''(u) = q'(u) = \frac{p e^u (1-p+pe^u) - (pe^u)^2}{(1-p+pe^u)^2} = \frac{pe^u(1-p)}{(1-p+pe^u)^2}
\end{equation} L ′′ ( u ) = q ′ ( u ) = ( 1 − p + p e u ) 2 p e u ( 1 − p + p e u ) − ( p e u ) 2 = ( 1 − p + p e u ) 2 p e u ( 1 − p ) 观察可知,L ′ ′ ( u ) L''(u) L ′′ ( u ) q ( u ) ( 1 − q ( u ) ) q(u)(1-q(u)) q ( u ) ( 1 − q ( u ))
根据泰勒公式(带拉格朗日余项),存在一个 ξ \xi ξ 0 0 0 u u u
L ( u ) = L ( 0 ) + L ′ ( 0 ) u + 1 2 L ′ ′ ( ξ ) u 2 \begin{equation}
L(u) = L(0) + L'(0)u + \frac{1}{2} L''(\xi)u^2
\end{equation} L ( u ) = L ( 0 ) + L ′ ( 0 ) u + 2 1 L ′′ ( ξ ) u 2 我们已知:L ( 0 ) = ln ( 1 − p + p ) = 0 L(0) = \ln(1-p+p) = 0 L ( 0 ) = ln ( 1 − p + p ) = 0 L ′ ( 0 ) = 0 L'(0) = 0 L ′ ( 0 ) = 0 z z z f ( z ) = z ( 1 − z ) f(z) = z(1-z) f ( z ) = z ( 1 − z ) 1 4 \frac{1}{4} 4 1 z = 1 / 2 z = 1/2 z = 1/2 q ( ξ ) = p e ξ 1 − p + p e ξ q(\xi) = \frac{pe^\xi}{1-p+pe^\xi} q ( ξ ) = 1 − p + p e ξ p e ξ ( 0 , 1 ) (0, 1) ( 0 , 1 )
L ′ ′ ( ξ ) = q ( ξ ) ( 1 − q ( ξ ) ) ≤ 1 4 \begin{equation}
L''(\xi) = q(\xi)(1-q(\xi)) \le \frac{1}{4}
\end{equation} L ′′ ( ξ ) = q ( ξ ) ( 1 − q ( ξ )) ≤ 4 1 将这些结果代入泰勒展开式:
L ( u ) ≤ 0 + 0 + 1 2 ⋅ 1 4 ⋅ u 2 = u 2 8 \begin{equation}
L(u) \le 0 + 0 + \frac{1}{2} \cdot \frac{1}{4} \cdot u^2 = \frac{u^2}{8}
\end{equation} L ( u ) ≤ 0 + 0 + 2 1 ⋅ 4 1 ⋅ u 2 = 8 u 2 最后,我们将 u = s ( b − a ) u = s(b-a) u = s ( b − a )
ln ( E [ e s X ] ) ≤ L ( s ( b − a ) ) ≤ s 2 ( b − a ) 2 8 \begin{equation}
\ln(\mathbb{E}[e^{sX}]) \le L(s(b-a)) \le \frac{s^2(b-a)^2}{8}
\end{equation} ln ( E [ e s X ]) ≤ L ( s ( b − a )) ≤ 8 s 2 ( b − a ) 2 两边同时取指数,即得霍夫丁引理的最终形式:
E [ e s X ] ≤ exp ( s 2 ( b − a ) 2 8 ) \begin{equation}
\mathbb{E}[e^{sX}] \le \exp\left( \frac{s^2(b-a)^2}{8} \right)
\end{equation} E [ e s X ] ≤ exp ( 8 s 2 ( b − a ) 2 ) 这个推导揭示了霍夫丁不等式:在任何有界随机变量的波动,对数矩生成空间中,都被一个方差为 ( b − a ) 2 4 \frac{(b-a)^2}{4} 4 ( b − a ) 2 1 / 8 1/8 1/8 1 / 2 1/2 1/2 1 / 2 1/2 1/2 z ( 1 − z ) z(1-z) z ( 1 − z ) 1 / 4 1/4 1/4
霍夫丁不等式:概率浓缩的终极形态将霍夫丁引理代入切尔诺夫界,并考虑 n n n X 1 , … , X n X_1, \dots, X_n X 1 , … , X n μ \mu μ [ a , b ] [a, b] [ a , b ] X ˉ n = 1 n ∑ X i \bar{X}_n = \frac{1}{n} \sum X_i X ˉ n = n 1 ∑ X i s s s s = 4 n ϵ ( b − a ) 2 s = \frac{4n\epsilon}{(b-a)^2} s = ( b − a ) 2 4 n ϵ
P ( X ˉ n − μ ≥ ϵ ) ≤ exp ( − 2 n ϵ 2 ( b − a ) 2 ) \begin{equation}
\mathbb{P}(\bar{X}_n - \mu \ge \epsilon) \le \exp\left( - \frac{2n\epsilon^2}{(b-a)^2} \right)
\end{equation} P ( X ˉ n − μ ≥ ϵ ) ≤ exp ( − ( b − a ) 2 2 n ϵ 2 ) 从无知到信心的飞跃霍夫丁不等式的出现,很好的改变了智能体对不确定性的理解。我们可以从这个公式中得出几个结论:样本量 n n n n n n δ \delta δ exp ( − 2 n ϵ 2 ) = δ \exp(-2n\epsilon^2) = \delta exp ( − 2 n ϵ 2 ) = δ ϵ \epsilon ϵ
ϵ = ln ( 1 / δ ) 2 n \begin{equation}
\epsilon = \sqrt{\frac{\ln(1/\delta)}{2n}}
\end{equation} ϵ = 2 n ln ( 1/ δ ) 这就是为什么在 UCB(置信上限)算法中,探索项总是包含 ln ( t ) / n \sqrt{\ln(t)/n} ln ( t ) / n δ \delta δ < ϵ <\epsilon < ϵ
Mathematical derivation of the UCB algorithm
在建立了霍夫丁不等式的指数级缩放之后,我们终于拥有了量化的工具。在强化学习的语境下,这种无知体现为智能体面临的探索与利用(Exploration vs. Exploitation) 之苦。如果我们仅仅采取贪心策略(Greedy),智能体可能会陷入局部最优的陷阱,永远无法触及未曾探索的高奖励区域。
为了解决这一矛盾,本章将利用前述的不等式,构建一套具有数理保障的探索机制。我们将以多臂老虎机(Multi-Armed Bandit, MAB)这一最简决策模型为切入点,演示霍夫丁不等式是如何演化为 UCB (Upper Confidence Bound) 算法的。
Optimism in the Face of Uncertainty
在数理决策中,OFU 原则是一套极具“进取心”的逻辑。它的核心思想是:对于任何一个动作,其真实的期望价值 μ a \mu_a μ a μ ^ a \hat{\mu}_a μ ^ a U t ( a ) U_t(a) U t ( a ) μ a \mu_a μ a
μ a ≤ μ ^ a ( t ) + U t ( a ) \begin{equation}
\mu_a \le \hat{\mu}_a(t) + U_t(a)
\end{equation} μ a ≤ μ ^ a ( t ) + U t ( a ) 算法的行为准则便是:永远选择那个“置信上限”最高的动作。从霍夫丁不等式推导 UCB 指数假设对于某个动作 a a a t t t N t ( a ) N_t(a) N t ( a )
P ( μ a ≥ μ ^ a ( t ) + ϵ t ) ≤ exp ( − 2 N t ( a ) ϵ t 2 ) \mathbb{P}\left( \mu_a \ge \hat{\mu}_a(t) + \epsilon_t \right) \le \exp\left( -2 N_t(a) \epsilon_t^2 \right) P ( μ a ≥ μ ^ a ( t ) + ϵ t ) ≤ exp ( − 2 N t ( a ) ϵ t 2 ) 我们令 δ t \delta_t δ t
exp ( − 2 N t ( a ) ϵ t 2 ) = δ t \begin{equation}
\exp\left( -2 N_t(a) \epsilon_t^2 \right) = \delta_t
\end{equation} exp ( − 2 N t ( a ) ϵ t 2 ) = δ t 通过对数变换求解误差项 ϵ t \epsilon_t ϵ t
− 2 N t ( a ) ϵ t 2 = ln ( δ t ) ⟹ ϵ t = − ln ( δ t ) 2 N t ( a ) \begin{equation}
-2 N_t(a) \epsilon_t^2 = \ln(\delta_t) \implies \epsilon_t = \sqrt{\frac{-\ln(\delta_t)}{2 N_t(a)}}
\end{equation} − 2 N t ( a ) ϵ t 2 = ln ( δ t ) ⟹ ϵ t = 2 N t ( a ) − ln ( δ t ) 随时间衰减的出错概率在动态的决策序列中,随着总步数 t t t δ t \delta_t δ t δ t = t − 4 \delta_t = t^{-4} δ t = t − 4 δ t = t − 4 \delta_t = t^{-4} δ t = t − 4
ϵ t = − ln ( t − 4 ) 2 N t ( a ) = 4 ln t 2 N t ( a ) = 2 ln t N t ( a ) \begin{equation}
\epsilon_t = \sqrt{\frac{-\ln(t^{-4})}{2 N_t(a)}} = \sqrt{\frac{4 \ln t}{2 N_t(a)}} = \sqrt{\frac{2 \ln t}{N_t(a)}}
\end{equation} ϵ t = 2 N t ( a ) − ln ( t − 4 ) = 2 N t ( a ) 4 ln t = N t ( a ) 2 ln t 由此,我们推导出著名的 UCB 索引公式:
A t = arg max a ∈ A [ Q ^ t ( a ) + c ln t N t ( a ) ] \begin{equation}
A_t = \arg\max_{a \in \mathcal{A}} \left[ \hat{Q}_t(a) + c \sqrt{\frac{\ln t}{N_t(a)}} \right]
\end{equation} A t = arg a ∈ A max [ Q ^ t ( a ) + c N t ( a ) ln t ] Temporal difference learning and the bootstrapping principle
在完成了针对经验均值缩放的定量分析后,我们已经能够利用霍夫丁不等式为“样本均值”划定置信边界。然而,蒙特卡罗(MC)方法在数理结构上存在一个内禀的缺陷:它依赖于完整轨迹的回报 G t G_t G t G t G_t G t R t + k R_{t+k} R t + k
为了克服这一“路径方差陷阱”,我们必须回到贝尔曼方程的递归本质。如果说 MC 是在路径空间进行全局积分,那么时序差分(Temporal Difference, TD)学习则是利用微分思想,将全局的价值估计坍缩为局部的时间步迭代。这一跃迁标志着强化学习从“离线轨迹平均”向“在线自举更新”的数理范式转移。
TD 学习的逻辑核心在于自举(Bootstrapping),即利用后续状态的估计值来更新当前状态的估计。这一思想直接源于第一节推导出的贝尔曼期望方程:
V π ( s ) = E π [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s ] V^\pi(s) = \mathbb{E}_\pi [R_{t+1} + \gamma V^\pi(S_{t+1}) \mid S_t = s] V π ( s ) = E π [ R t + 1 + γ V π ( S t + 1 ) ∣ S t = s ] 在无模型设定下,我们无法直接计算期望 E \mathbb{E} E ( S t , A t , R t + 1 , S t + 1 ) (S_t, A_t, R_{t+1}, S_{t+1}) ( S t , A t , R t + 1 , S t + 1 ) G t T D = R t + 1 + γ V ( S t + 1 ) G_t^{TD} = R_{t+1} + \gamma V(S_{t+1}) G t T D = R t + 1 + γV ( S t + 1 ) V ( S t + 1 ) V(S_{t+1}) V ( S t + 1 )
我们定义 TD 误差(TD Error) δ t \delta_t δ t
δ t = R t + 1 + γ V ( S t + 1 ) − V ( S t ) \begin{equation}
\delta_t = R_{t+1} + \gamma V(S_{t+1}) - V(S_t)
\end{equation} δ t = R t + 1 + γV ( S t + 1 ) − V ( S t ) 基于随机逼近理论(Stochastic Approximation),我们构建如下更新规则:
V ( S t ) ← V ( S t ) + α δ t \begin{equation}
V(S_t) \leftarrow V(S_t) + \alpha \delta_t
\end{equation} V ( S t ) ← V ( S t ) + α δ t 其中 α \alpha α
TD 学习引入自举机制后,深刻地改变了估计量的数理性质。这构成了强化学习中著名的偏置-方差权衡(Bias-Variance Tradeoff)。在蒙特卡罗方法中,目标值 G t = ∑ γ k R t + k + 1 G_t = \sum \gamma^k R_{t+k+1} G t = ∑ γ k R t + k + 1 V π ( s ) V^\pi(s) V π ( s ) G t G_t G t Var ( G t ) \text{Var}(G_t) Var ( G t )
相比之下,TD 目标 R t + 1 + γ V ( S t + 1 ) R_{t+1} + \gamma V(S_{t+1}) R t + 1 + γV ( S t + 1 )
低方差(Low Variance):TD 目标仅受单步随机性(R t + 1 R_{t+1} R t + 1 S t + 1 S_{t+1} S t + 1 V ( S t + 1 ) V(S_{t+1}) V ( S t + 1 )
有偏性(Biased):在学习初期,由于 V ( S t + 1 ) V(S_{t+1}) V ( S t + 1 )
从数理放缩的角度看,TD 学习通过引入可控的“计算性偏置”换取了“统计性方差”的剧烈下降。这解释了为什么在实际工程中,TD 方法通常比 MC 表现出更优越的样本效率,因为它在每一时刻都在利用已有的知识(自举)来缩窄未知的搜索边界。批量更新与收敛动力学在分析 TD 学习的收敛性时,一个重要的数理视角是将其视为一种算子逼近。在给定一系列采样轨迹的背景下,TD(0) 实际上是在寻找一个最优的线性函数映射,使得在这些采样样本上的贝尔曼剩余平方和最小。
对于有限状态 MDP,TD(0) 已被证明能以概率 1 收敛至真实价值 V π V^\pi V π V V V
从单步到长程的谱系TD(0) 仅仅是价值估计谱系的一个极端(只看一步),而 MC 是另一个极端(看无穷步)。两者之间存在着广阔的中间地带——n 步时序差分(n-step TD)。
G t : t + n = R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n V ( S t + n ) \begin{equation}
G_{t:t+n} = R_{t+1} + \gamma R_{t+2} + \dots + \gamma^{n-1} R_{t+n} + \gamma^n V(S_{t+n})
\end{equation} G t : t + n = R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n V ( S t + n ) 随着 n n n λ \lambda λ